


Stages of development of a genomic surveillance program
It takes a lot more than buying a sequencing instrument!

Getting started
Every public health agency that wants to incorporate pathogen genomic data into its daily work has to go through a number of steps to build out to full capacity. I often represent this as a bridge, but today I’ll use a pyramid analogy. It’s not perfect, and some of the steps can be done in parallel (especially the top 4), but I think it’s a useful example.
Because building pathogen genomics into existing disease surveillance programs is such a complex task, breaking it down into component steps with goals along the way can help set a roadmap for your agency. So lets start from the bottom of the pyramid and work our way up!
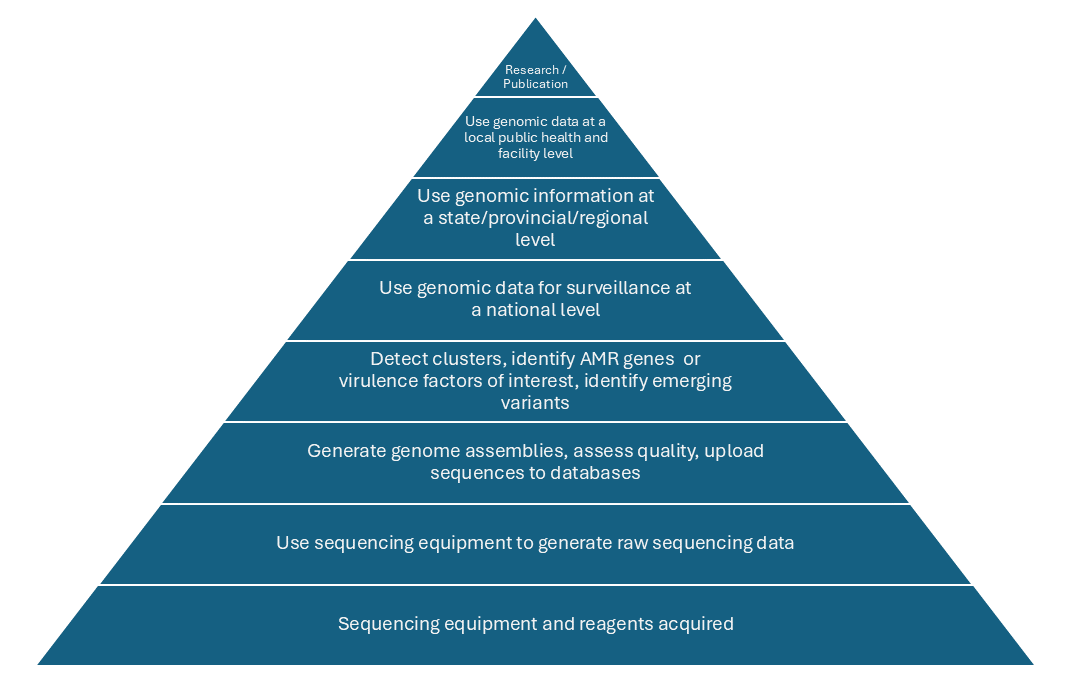
1. Acquiring sequencing equipment and reagents
This step often comes as a result of an influx of money, and this was especially true of pandemic money. Sometimes the money comes with specifications (we will give you money for 1 MiSeq), and other times it’s more open-ended. If you’re in the position to decide which sequencing equipment to purchase, there are a number of factors to consider.
Sequencing volume: High-throughput instruments are great for being cost-effective, but if you’re a small volume lab, your turnaround time may be too slow to be helpful if you’re waiting to fill up a high-volume machine.
Redundancy: For critical systems is may be better to get two smaller machines so you have redundancy in case of instrument failure.
Space: Sequencing instruments vary greatly in size! Take stock of your physical infrastructure to make sure you have the right floor space, bench space, electrical plugs, etc.
Networks: Are you part of a surveillance network that requires you to submit data from one particular type of instrument?
Reagents: Both the cost and the availability need to be considered.
There are many more consideration, and it’s well worth taking the time to brainstorm with your team before making such a major investment.
2. Assembling genomes, quality control, data upload
Once you’re past stage one and you’re reliably generating sequencing data using the equipment purchased, you’ll need to have a plan in place for how to analyze that data. The raw data that comes of the sequencing instruments (outside of some all-in-one solutions that incorporate an instrument with bioinformatics tools) is of no use unless it’s appropriately processed and analyzed.
Some of the things to consider at this stage include:
Staffing: Depending on the agencies, you may have a bioinformatician on staff, upskill existing laboratory scientists to learn bioinformatics, lean on academic or reference centers, use commercial software, or contract with companies that provide bioinformatics services.
Validation: Will the data be used for surveillance purposes or will it be used for clinical decision-making? Each country has a unique regulatory environment, and it’s important to think through how your bioinformatics processes need to be accredited as part of an overall validation of sequencing assays.
Analysis tools: Will you be tapping into existing analysis pipelines and systems set up by reference centers, or will you be responsible for building or selecting your own tools?
Data storage: Where will you keep the sequencing data? Will it be shared in public sequencing repositories such as NCBI or the ENA? What are the IT guidelines on local and cloud storage of data?
3. Cluster detection, AMR and virulence factors, identify emerging variants, etc.
Once you’re reliably generating and processing sequencing data, it’s time for the real fun to begin! At this stage, a few questions are:
Analyses - What analyses are important? This is were collaboration between bioinformaticians and epidemiologists is critical. This will have to be done for each pathogen or group of pathogens, both because the questions are unique to each pathogen, and because there are often different staff members working in each disease area.
Data sharing: Within your agency, who will have access to what data? It can be scary to share data, because you never know how people will interpret and use the data. But the alternative of not sharing is worse. Build trust with your colleagues, teach each other about your respective disciplines, analyses methods, and needs, and then share as freely as possible.
Data systems: This is a big one! It’s not uncommon for reference centers to share back trees as images in powerpoint or a pdf, making it impossible for epidemiologists to overlay any of their data. Think through how data will actually flow between groups and what systems will be used to analyze and visualize that data.
4-6. Incorporating genomic data into national surveillance, regional, and local
Often, national (or international) level programs will provide equipment and funding for staff at regional centers to generate sequencing data for use in national level surveillance. As national level programs typically have more resources, they are often the first to be able to incorporate pathogen genomic in a comprehensive way. While this can be efficient, if local data generators are not empowered to use the data, they will be less motivated to participate, and public health won’t be getting the best value out of the data. The goal should always be to ensure that the data can be understood and used at all levels of the public system, as well as in community facilities such as hospitals, prisons, etc. This requires establishing a number of workstreams:
Data infrastructure that allows both for unified national processing and storage, but also for local access to processed data, as well as the ability to run local pipelines and tools if desired.
People infrastructure at all levels of public health. This is particularly challenging as you get down to a local level, where small agencies are not going to be able to have dedicated staff for bioinformatics and genomic epidemiology. Approaches such as regional resources and partnerships with academic organizations can help address the gaps, but ultimately the entire public health infectious disease workforce needs to be given the training necessary to have a basic level of comfort with interpreting processed genomic data. This is a whole separate post on it’s own though, so I’ll stop here!
Cross-functional communication is required to get the data out of the laboratory and into the epidemiologists workflows. Genomic epidemiology is not just adding back a few metadata points to a tree, it’s about incorporating genomic data into existing surveillance systems and workflows. And that takes time, training, thoughtful system design, and close collaboration between laboratory and epidemiology.
7. Research and publication
Though this one is listed at the top of the pyramid, it can be incorporated earlier along the way. I put it here because it’s not the primary initial goal of pathogen genomics in public health. This is what distinguishes public health from academia. The first goal is always to use the data for public health action, decisions, and the public good. But ultimately fulfilling that mission requires taking the systems that have been built and analyzing their outputs. This is applied public health research!
When a pathogen surveillance system has built all the base layers to create a representative, ongoing, integrated surveillance system, that system generates an amazing integrated dataset with rich clinical and epidemiological data joined with the sequencing information. Those datasets can and should be used to answer critical public health questions and generate and share knowledge through publications, presentations, and workshops.
Depending on the capabilities of an agency, this level may require collaborations with academic agencies or other agencies to bring together a team with the right types of expertise. This presents a tremendous opportunity to strengthen the relationship between public health and academia, as well as upskills public health employees who may not have had as many opportunities for formal analysis and publication in their applied public health career.
Conclusions
I hope that’s a helpful overview of some of the broad steps that an agency can expect to walk through on their way toward building integrated pathogen surveillance systems. I look forward to a future where many of these concepts are baked into our public health training programs, and ‘design of genomic surveillance systems’ is a special topic course available to every MPH or PhD student. For now, I’m thrilled to see the progress that so many agencies have been making!